导读:3月27日,通义千问Qwen系列中的全新多模态大模型Qwen2.5-Omni宣布开源。Qwen2.5-Omni作为通义系列模型中首个端到端全模态大模型,可以同时处理包括文本、图像、音频和视频等多种输入,并实时合成输出文本与自然语音。这意味着,用户可以和Qwen进行语音聊天和视频通话,有网友对此表示强烈欣喜。事实上,在一系列同等规模的单模态模型权威基准测试中,Qwen2.5-Omni在语音生成测 ……
3月27日,通义千问Qwen系列中的全新多模态大模型Qwen2.5-Omni宣布开源。

Qwen2.5-Omni作为通义系列模型中首个端到端全模态大模型,可以同时处理包括文本、图像、音频和视频等多种输入,并实时合成输出文本与自然语音。
这意味着,用户可以和Qwen进行语音聊天和视频通话,有网友对此表示强烈欣喜。

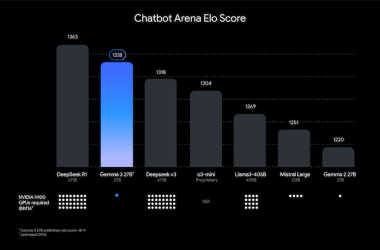
事实上,在一系列同等规模的单模态模型权威基准测试中,Qwen2.5-Omni在语音生成测评分数上达到了与人类持平的能力,这为该模型在语音和视频通话的可行性上提供了数据层面的支撑。

在具体技术上,Qwen2.5-Omni采用了通义团队全新首创的Thinker-Talker双核架构、Position Embedding融合音视频技术、位置编码算法TMRoPE(Time-aligned Multimodal RoPE)。
双核架构Thinker-Talker让Qwen2.5-Omni拥有了人类的“大脑”和“发声器”。Thinker负责处理和理解用户输入的内容,Talker则输出相应的语音标记。通过两者的配合完成了端到端的统一模型架构,将实时语义理解与语音生成形成协同。

TMRoPE则通过时间轴对齐实现视频与音频输入的精准同步,使得模型能够准确地捕捉到不同模态数据在时间维度上的对应关系,从而为生成连贯、准确的内容。
值得注意的是,Qwen2.5-Omni以7B的小尺寸让全模态大模型在产业上的广泛应用成为可能。用户在手机上,也能轻松部署和应用Qwen2.5-Omni模型。
目前,开发者和企业可免费下载商用Qwen2.5-Omni。
本文系观察者网独家稿件,未经授权,不得转载。










评论前必须登录!
注册