字节首创覆盖11+编程场景的全能代码大模型基准FullStack Bench
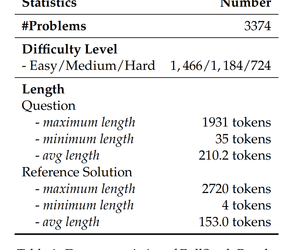
代码大模型越来越卷,评估AI编程水平的“考卷”也被迫升级。12月5日,字节豆包大模型团队开源最新代码大模型评估基准FullStack Bench,在业界首次囊括编程全栈技术中超11类真实场景,覆盖16种编程语言,包含3374个问题,相比此前基准,可以更有效地评估大模型在现实世界 ......
代码大模型越来越卷,评估AI编程水平的“考卷”也被迫升级。12月5日,字节豆包大模型团队开源最新代码大模型评估基准FullStack Bench,在业界首次囊括编程全栈技术中超11类真实场景,覆盖16种编程语言,包含3374个问题,相比此前基准,可以更有效地评估大模型在现实世界 ......