全新分布式优化器融合全球算力,LLM训练通信量降低万倍
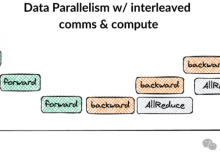
编辑:alan 【新智元导读】 近日,Nous Research宣布了一项重大突破,通过使用与架构和网络无关的分布式优化器,研究人员成功将训练LLM时GPU间的通信量降低了1000到10000倍!如果可以使用世界上所有的算力来训练AI模型,会怎么样? 近日,凭借发布了开源的He...
编辑:alan 【新智元导读】 近日,Nous Research宣布了一项重大突破,通过使用与架构和网络无关的分布式优化器,研究人员成功将训练LLM时GPU间的通信量降低了1000到10000倍!如果可以使用世界上所有的算力来训练AI模型,会怎么样? 近日,凭借发布了开源的He...

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyun ......
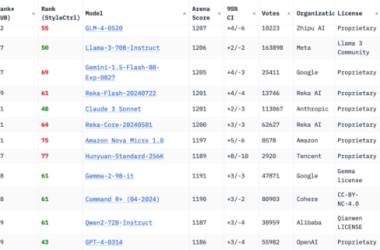
从某种意义上说,2024年不仅是技术突破的一年,更是行业走向成熟的重要转折点。这一年,GPT-4级别的模型不再罕见,许多机构都开发出了性能超越GPT-4的模型;这一年,运行效率显著提高,成本急剧下降;这一年,多模态LLM,特别是支持图像、音频和视频处理的模型,变得越 ......